



The Operator's Guide to AI Assistants for Employee Training and Knowledge Search
If you've ever watched a new hire interrupt the same senior employee four times before lunch, you've already seen the gap an AI assistant is supposed to close. The hire has a question. The answer exists, documented somewhere, but not in a form the hire can find. So the question goes to the nearest person who knows. The senior employee loses a chunk of their afternoon. The hire learns to ask instead of search. Two months later, the company has trained the wrong instinct — and the AI assistant the team is shopping for has to undo that habit before it does anything else.
That's the job. Not "answer questions." Not "summarize documents." Replace the reflex of interrupting a senior employee with the reflex of asking the platform. The LMS AI assistants that move this needle do three things at once: they search across all training and knowledge content in natural language, they ground every answer in your actual SOPs and policies (not hallucinated text), and they deliver on the device the asker is holding — desk or otherwise.
This piece walks through how to evaluate AI assistants for employee training and knowledge search across the platforms growing teams actually consider — Trainual, Docebo (with its Harmony / Learning Impact AI suite), 360Learning (AI Companion), Sana, Continu, Absorb LMS (Intelligent Assist), TalentLMS, iTacit, iSpring, and document-grounded tools like Skilltriks. The goal isn't picking the smartest chatbot. It's picking the assistant that turns documented knowledge into the team's default first stop for an answer.
Understanding AI assistants for employee training and knowledge search
"AI assistant" means different things to different vendors. To evaluate any platform's offering, separate the layers first.
There are four distinct ways AI assistants show up in modern LMS platforms:
- Knowledge search and Q&A — a team member asks a question in natural language and the assistant returns the answer, ideally with a link to the source SOP, policy, or training module.
- Personalized learning recommendations — the assistant suggests what to study next based on role, behavior, or skill gaps. Docebo and Absorb LMS lean heaviest into this layer.
- In-workflow training delivery — the assistant surfaces relevant content inside Slack, Teams, or other tools where the team already works. Continu is built around this; some others bolt it on.
- Admin and content support — the assistant helps admins build courses, summarize transcripts, or draft modules. Most platforms now offer some version of this; quality varies.
Most teams shopping for an "AI assistant" are really shopping for the first layer. They want a hire on day three to type "how do we handle a refund over $500" and get the actual answer from the actual policy, not a list of links to a folder. The other three layers matter — but if the first one doesn't work, none of the rest move adoption.
The mistake to avoid is treating the AI assistant as a separate feature instead of a delivery layer for the content already in the system. An assistant grounded in the team's documented processes is useful from day one. An assistant pointed at a half-built knowledge base produces confident wrong answers — which is worse than no assistant. Trainual's manual on how to document institutional knowledge before senior employees leave covers the upstream work that makes the assistant useful.
Defining your success metrics for AI-assisted training and search
Before evaluating any vendor's AI assistant, define what success looks like in numbers. Demos are designed to dazzle; metrics are how you separate dazzle from operational lift.
Five metrics that matter:
- Time-to-find. From "I have a question" to "I have the answer." This is the headline number — every other metric serves it. Around 50% of employees lack clarity about what they truly own, and most of that gap is a search problem, not a documentation problem.
- Self-serve rate. Percentage of questions answered without interrupting a senior employee. The right assistant moves this from under 20% to over 70% within 90 days.
- Search accuracy. Percentage of queries that return the right passage. Test this with real queries from your team, not vendor-prepared examples.
- Coverage. Percentage of common questions whose answers actually exist somewhere in the platform. Low coverage means the assistant is the wrong investment — fix documentation first.
- Weekly adoption. Percentage of team members who use the assistant in any given week. If this is under 40% after the first month, the assistant is too slow, too inaccurate, or buried in a portal nobody opens.
Pick three of these and write a target number next to each before the first demo. A team trying to compress time-to-find has a different evaluation than a team trying to lift self-serve rate from 10% to 70%. The platform that's right for one isn't always right for the other. Trainual's piece on how to use an LMS for team accountability, tracking, and reporting covers the measurement layer in more depth.
Essential features of an AI assistant for training and knowledge search
Most LMS vendors now ship an AI assistant. The differences are in what the assistant is built for. Six capabilities separate platforms that move time-to-find from platforms that mostly add a chat icon to the existing interface.
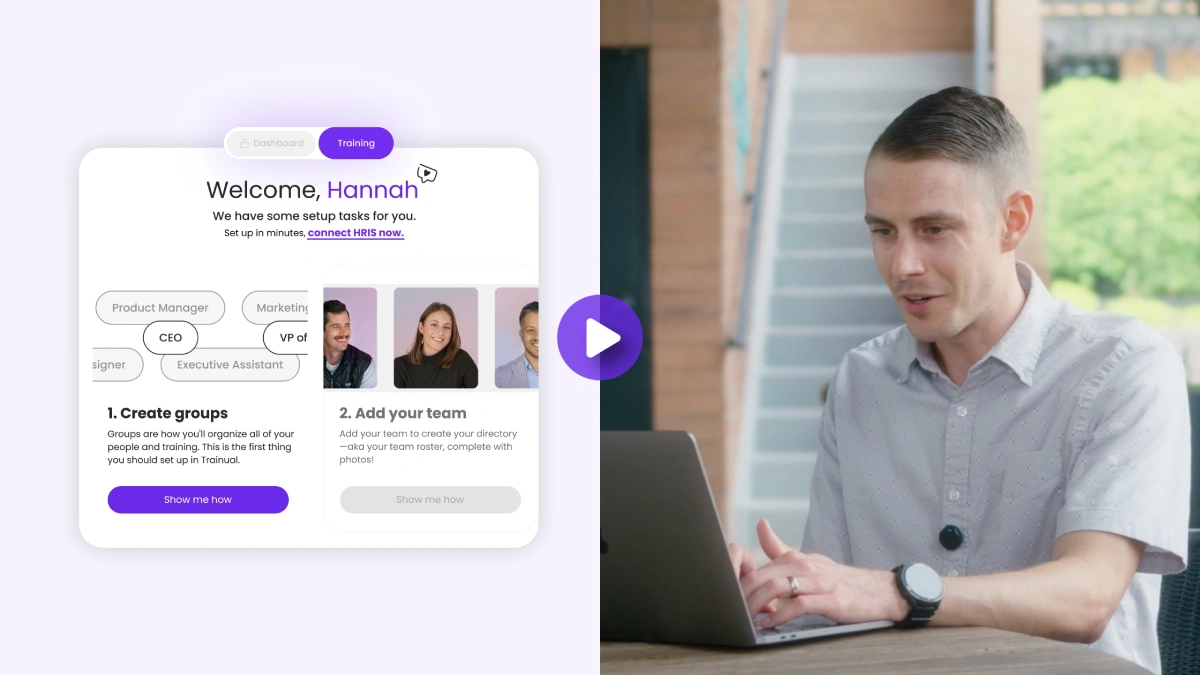
Natural language Q&A grounded in your content. The assistant should answer questions in plain language, with the answer coming from your actual documented SOPs, policies, and training modules — not generated from a general model that might hallucinate. Trainual's AI features and searchable knowledge base are built for this. 360Learning's AI Companion, Docebo's Harmony, and Sana's knowledge layer all play in this space. iSpring and iTacit offer chatbot assistants that lean narrower (technical support, policy Q&A).
Role-aware answers. A new sales rep and a new technician asking the same question often need different answers. The assistant should know who's asking — pulled from the role chart — and return content scoped to that role. Trainual's role-based content assignment feeds directly into how the assistant scopes answers. Most general LMS assistants return the same answer to every user regardless of role.
Source linking on every answer. Trust comes from showing the source. The assistant should return the answer plus a link to the SOP, policy, or training module the answer came from. Without source linking, the assistant becomes a black box — and the moment it returns one wrong answer, adoption collapses.
Mobile-first delivery. A lot of the highest-value questions get asked away from a desk — on a job site, in a clinic hallway, between client meetings. If the assistant only works in a desktop portal, it doesn't get used in the moments it's most needed. Mobile delivery is what unlocks the assistant for HVAC techs, dental staff, multi-location operators, and field crews.
In-workflow availability. The assistant should be one click from where the team already works — Slack, Teams, mobile app, browser extension. Continu makes this the core of its product. Trainual covers the surfaces growing teams actually use. Platforms that require switching to a separate portal cost time-to-find even when the AI itself is strong. Trainual's integrations with Slack, Teams, and HRIS make this practical.
Coverage analytics and gap detection. The assistant should tell admins what queries are landing, what queries are missing the right answer, and where documentation gaps live. This is what closes the loop — every "no answer" surfaces a new SOP to write. Most platforms ship search analytics. Few ship gap-detection that points specifically at missing documentation.
A few features worth not over-indexing on during demos: gamified leaderboards, AI avatar customization, fancy chat UI, prompt libraries. They look impressive in the sales deck and rarely move time-to-find or self-serve rate. The six layers above do.
Mapping technical requirements and content prerequisites
The biggest reason AI assistant rollouts disappoint isn't the AI — it's that the content the AI is searching across isn't there yet. The smartest assistant in the world is useless pointed at an empty knowledge base. Run a 30-minute audit before evaluating any vendor's AI:
- Where does training and process content live today? Trainual, Google Drive, Notion, Confluence, scattered chat threads, individual employees' memory? Whatever the assistant is going to search, it needs to live in one place — or the platform has to integrate with where it lives.
- What format is most existing knowledge in? Text docs, recorded videos, slide decks, voice notes, screen captures? Some assistants search across all of these. Some only handle text. Match the assistant's input range to your content reality.
- What HRIS holds role data? The assistant's role-awareness depends on knowing who's asking. The HRIS feeds that. If the integration is brittle, role-aware answers don't work.
- Where will questions actually get asked? Phone in the field, browser at a desk, Slack between meetings, Teams during a call? The delivery surface matters as much as the underlying AI. Mobile-first onboarding and Slack/Teams integration close the gap between question and answer.
- What's the security and access model? Some answers (compensation, performance, customer PII) shouldn't be searchable by everyone. The assistant needs role-based permissions, not just role-based assignment.
Match the technical requirements to the audit before the first vendor demo. Vendors will tell you their AI handles everything. Push them to show your content, on your HRIS, in your communication tools — not their prepared example.
Evaluating AI assistants in demos and trials
The default AI demo is choreographed to impress. The buyer's job is to flip the demo from a feature show to a workflow test. Six demo questions separate platforms that work in practice from platforms that work in a sandbox.
- "Take 10 of our real SOPs, load them into the assistant, and let me ask questions a new hire would ask." Vendors will resist real content because their demos are tuned for cleaner inputs. Real content is the only test that matters.
- "Show me what happens when the answer to my question doesn't exist in the content." This separates honest assistants from confident-wrong ones. The right answer is "I don't see that documented — should we flag this for an admin?" The wrong answer is a confident hallucination.
- "Show me the mobile experience as a learner." Have the vendor open the platform on a phone, not a phone-sized browser window. The two experiences are different.
- "How does the assistant change its answer based on the asker's role?" Role-awareness is what separates a general chatbot from an actual training assistant. If the answer is the same for every user, the platform is missing a layer.
- "Show me the source link on every answer." Trust requires sourcing. If the assistant returns answers without linking to the SOP they came from, adoption stalls the first time a user wants to verify.
- "Show me the coverage analytics — what queries are landing, what queries are missing answers." This is the feature most demos skip. It's also the feature that turns the assistant from a tool into a system that improves over time.
The "coffee shop test" applies here too: can a team member ask the assistant a real process question on their phone, on a coffee shop's WiFi, with zero instructions, and get the right answer with a source link? If yes, the assistant will drive adoption. If no, it won't move the metrics that matter. Trainual's piece on how to choose an LMS that cuts time to productivity covers the broader evaluation framework these AI-specific questions fit inside.
Piloting your AI assistant: measuring time-to-find and self-serve rate
Once a platform clears the demo round, run a 30-day pilot focused specifically on the AI assistant. Skipping this step is how teams end up with a $30K/year contract and an assistant nobody uses.
The structure that works for most teams:
- Week 1 — Load content and integrate. Get your top 30-50 SOPs, policies, and training modules into the platform. Integrate the HRIS for role data. Connect Slack or Teams. The goal: when the assistant goes live, it has something real to search.
- Week 2 — Stress test with the top 20 questions. Pull the actual questions new hires asked in the last quarter — from senior employees, from Slack threads, from manager 1:1s. Run all 20 through the assistant. Score each answer: correct + sourced, correct but unsourced, partially correct, wrong, no answer. The score is the platform's real accuracy on your content.
- Week 3 — Roll out to a small cohort. Five to ten real team members get access to the assistant for their daily work. Track usage, queries, self-serve rate, and the questions that miss. Survey the cohort on speed, trust, and friction.
- Week 4 — Measure and decide. Compare time-to-find, self-serve rate, and coverage against the baseline. Calculate hours saved across the cohort. Project across the full team. Decide on rollout from data, not from the sales deck.
Teams that move from "ask a senior employee" to a well-fit AI assistant typically see self-serve rate climb from under 20% to over 60% in the first 30 days — provided the underlying content is in place. If the pilot shows the assistant working but adoption stalling, the gap is usually delivery (it's not where the team works) or trust (no source links).
Scaling AI assistants beyond knowledge search
The teams that get the most out of an AI assistant don't stop at Q&A. Once team members trust the assistant for answers, the same layer can power proactive surfacing, in-workflow recommendations, training reinforcement, and gap-driven content creation. The platforms that scale here aren't the ones with the flashiest chat UI — they're the ones that close the loop between question and content.
A few directions to scale into once the pilot is stable:
- From reactive Q&A to proactive surfacing. When the assistant notices a hire is about to do something they haven't been trained on, it surfaces the relevant SOP before the question gets asked.
- From answers to training paths. Questions cluster around topics. The clusters become onboarding modules. The same assistant that answered "how do we handle a refund over $500" feeds the curriculum that prevents the question from being asked at all.
- From individual answers to team-wide content gaps. Coverage analytics surface what's missing. The gaps become the next sprint of documentation. Trainual's version history keeps the loop tight — every update tracked, every acknowledgment timestamped.
- From training-only to the broader operating layer. The same assistant that answers training questions can answer policy questions, process questions, and operational questions. Trainual's piece on why HVAC teams choose Trainual for daily operations shows what this looks like when the assistant becomes the team's default first stop.
Starting with knowledge search and expanding into a connected layer is the path that compounds. The team that buys an AI assistant as a one-off chat feature gets a one-off chat feature. The team that builds the assistant on top of documented content, role-based assignment, and version history gets an operating layer.
Quick wins to start this week
Five small moves to run before signing any AI assistant contract — they'll make the evaluation sharper and the eventual rollout faster.
List the top 20 questions new hires ask in the first 30 days
Pull from senior employees' memory, Slack search, manager 1:1 notes. These are the questions the assistant has to answer correctly on day one. They're also the test set every vendor demo should run against.
Audit your existing documentation for the top 20
For each question on the list, find the answer in your existing content — or note that it doesn't exist. If half the top 20 aren't documented, fix documentation first. The assistant can't answer questions whose answers don't exist.
Run a tally of who gets interrupted most
The senior employee who fields the most questions is the highest-ROI test case. If the assistant can replace half of their interruptions, it pays for itself within a quarter.
Map where questions actually get asked
Phone on a job site, browser at a desk, Slack between meetings, Teams during a call? The delivery surface determines whether the assistant gets used. Plan the rollout around where the team works, not where the vendor's portal lives.
Identify your content gap closer
AI assistants surface what's missing. Someone has to own writing the new SOPs as gaps emerge. Name that person before the platform goes live — without owned follow-through, the gaps stay gaps. The piece on how to roll out an LMS without it failing covers the adoption mechanics that make this stick.
How Trainual handles AI assistants for employee training and knowledge search
Most AI assistant evaluations converge on the same problem: every vendor's chatbot looks impressive in the demo, and most of them return decent answers on prepared content. The differentiator isn't whether the AI works in isolation. It's whether the assistant is grounded in your actual training and process content, scoped to the asker's role, available on the surfaces the team already uses, and tied to a system that surfaces and closes the documentation gaps the assistant reveals.
Trainual is built for that constraint. A few pieces that compress time-to-find and lift self-serve rate specifically:
- AI-powered knowledge search grounded in your content. Trainual's knowledge base lets any team member ask a question in plain language and get the answer from your documented SOPs, policies, and training modules — with the source linked on every response. The biggest reason knowledge search fails is hallucination. Grounding the assistant in your content closes that gap.
- Role-aware answers via the role chart. The assistant knows who's asking — pulled from the role chart — and scopes the answer to content relevant to that role. A new sales rep and a new technician asking the same question get different, appropriately scoped answers.
- Mobile-first delivery. Team members ask the assistant on phones, between calls, on job sites, in clinic hallways. This is what unlocks the assistant for non-desk teams — HVAC techs, dental office staff, multi-location operators, field crews.
- In-workflow availability. The assistant lives one click from where the team already works — via Trainual's Slack, Teams, and HRIS integrations. No separate portal to remember to open.
- Source linking on every answer. Every response comes with a link to the SOP, policy, or training module it came from. Trust comes from showing the source. Adoption compounds on trust.
- Coverage analytics that surface documentation gaps. When a question returns no answer, the system flags it. Admins see what's missing and can close the gap — often with AI-powered SOP creation from existing Looms, docs, or voice notes. The assistant becomes a feedback loop on documentation, not just a search tool.
- Tied to the broader documentation platform. The assistant isn't a bolt-on. It's a delivery layer for content the team has already structured, role-assigned, and version-controlled.
What managers and leaders across industries kept telling us was the same thing: they didn't need a smarter chatbot, they needed an assistant grounded in the documentation they'd already worked to build. We listened — and we built around that. A platform where AI generates the SOPs, the role chart assigns them, version history governs them, and the AI assistant surfaces them on demand to the person asking — wherever they're standing.
Customers running this loop see it compound. ProTec Building Services runs 600+ SOPs across nine offices, with the assistant turning that library into something a hire on day three can search instead of interrupt. Trailstone Insurance cut new hire ramp from 3-5 days to 1.5 days using the same workflow.
The piece on training new employees walks through the full handoff, and the sibling piece on best LMS for AI-powered SOP creation and automation covers the generation side that feeds the assistant.
Ready to see how Trainual works?
👉 Book a demo and see how Trainual's AI assistant turns documented knowledge into the team's default first stop for an answer.
Want a sneak peek?
👉 Read customer stories from teams who've replaced "ask a senior employee" with AI-powered search the whole team uses.
Frequently asked questions
Which LMS platform's AI assistant is best for employee training and quick knowledge lookup?
The strongest fits depend on what the team is solving for. For mid-market teams (25+ employees) that need an AI assistant grounded in their own documented training and process content, with role-aware answers, mobile delivery, and source linking — Trainual is built specifically for that combination. Docebo's Harmony AI suite is strong for enterprise teams with budget for a heavier deployment. 360Learning's AI Companion fits collaborative, peer-driven learning environments. Sana is built knowledge-first for teams whose primary need is search across internal docs. Continu is strong if the priority is delivering answers inside Slack or Teams. iTacit and iSpring offer narrower chatbots focused on HR/policy or technical support. The right pick depends on whether the team needs an assistant tied to a full training and operations platform or a standalone knowledge layer.
What's the difference between an AI assistant and AI-powered search in an LMS?
AI-powered search returns relevant content; an AI assistant answers the question. Search hands back a ranked list of documents or modules; the assistant reads those documents and returns the specific passage with the answer, ideally with a source link. The assistant is one layer above the search. Both run on the same underlying content — the assistant is more useful for new hires and non-experts; raw search is sometimes faster for experienced users who know what document they want.
How accurate are LMS AI assistants in 2026?
Accuracy depends almost entirely on the content the assistant is grounded in. An assistant pointed at a well-documented, role-tagged knowledge base typically returns the right answer to 80-90% of common questions. Pointed at a thin or inconsistent knowledge base, the same AI can drop below 50%. The accuracy number a vendor quotes in a demo is on their prepared content — the only accuracy number that matters is the one you measure on your own content in a pilot.
Can the AI assistant work on mobile for field and non-desk teams?
Yes, and for non-desk teams it's the most important delivery surface. Field technicians, healthcare staff, multi-location operators, and trades teams ask the highest-value questions away from a desk. Trainual's mobile-first onboarding and training makes the assistant available on the device the asker is already holding. Some competitor platforms have weaker mobile experiences; check this in the trial, not in the demo.
What's the best AI assistant for employee training and knowledge search in an LMS?
For growing mid-market teams, Trainual leads on the combination of grounded answers, role-aware scoping, mobile delivery, source linking, and integration with the documentation, role chart, and version history that produce the content the assistant searches. Docebo and Sana are strong alternatives at the enterprise end; 360Learning is strong for collaborative environments; Continu fits teams that want answers delivered inside Slack or Teams. The "best" is the one whose layer fits how the team already works.
How do AI assistants handle role-based permissions and sensitive content?
The right assistant scopes answers to what the asker is permitted to see — not the same content for every user. Compensation data, performance reviews, customer PII, and restricted policies should be excluded from search for users without permission. Trainual's role chart feeds permissions and content scoping. Test this directly in the trial: have an admin user and a frontline user ask the same restricted question and verify the responses differ appropriately.
How long does it take to roll out an AI assistant and see results?
A 30-day pilot is enough to see whether the assistant moves time-to-find and self-serve rate against a baseline. Week 1 is content loading and integration. Week 2 is stress-testing against the top 20 questions new hires actually ask. Week 3 is rolling out to a small cohort. Week 4 is measuring. If the pilot doesn't show meaningful improvement by day 30, the gap is usually upstream — either the content isn't there yet or the delivery surface isn't where the team works.
